

DeepMind, la empresa líder en inteligencia artificial ha presentado su más reciente innovación en el campo de la robótica: el Robotic Transformer 2 (RT-2). Este modelo vision-language-action (VLA) no solo promete revolucionar el campo de la robótica, sino que también establece un nuevo estándar en la integración de la visión y el lenguaje en la acción robótica.
Un Vistazo al RT-2: Aprendizaje de Datos Web y Robóticos
El RT-2 no es un modelo común. A diferencia de los modelos de visión-lenguaje (VLM) que se entrenan exclusivamente en conjuntos de datos a escala web, el RT-2 combina este aprendizaje con datos robóticos recopilados de primera mano. Esto significa que, en lugar de depender únicamente de patrones de lenguaje y visuales recopilados de la web, el RT-2 también integra experiencias prácticas de robots en entornos del mundo real.
Este enfoque híbrido tiene un propósito claro: permitir que los robots alcancen un nivel de competencia similar al de los sistemas VLM en términos de reconocimiento de patrones visuales y lingüísticos. Al combinar el vasto conocimiento de la web con experiencias robóticas prácticas, el RT-2 puede traducir instrucciones lingüísticas en acciones robóticas precisas y contextualizadas.
Construyendo sobre el Legado del RT-1
El RT-2 no surgió de la nada. Se basa en el éxito y las lecciones aprendidas del Robotic Transformer 1 (RT-1). El RT-1 fue un pionero en su tiempo, siendo un modelo que aprendió de demostraciones multitarea en entornos específicos. Durante 17 meses, el RT-1 recopiló datos de 13 robots diferentes en un entorno de cocina de oficina, aprendiendo y adaptándose a las tareas y desafíos presentados en ese entorno.
Sin embargo, el RT-2 lleva este aprendizaje un paso más allá. No solo retiene las capacidades del RT-1, sino que también muestra una mejora significativa en la generalización, la comprensión semántica y visual, y la capacidad de interpretar y actuar sobre comandos nuevos y desconocidos. Estas mejoras son evidentes en la capacidad del RT-2 para realizar razonamientos rudimentarios, como decidir qué objeto podría usarse como un martillo improvisado o determinar la bebida más adecuada para una persona cansada.
El Futuro de la Robótica: Habilidades Emergentes y Control Avanzado
El RT-2 no es solo una mejora incremental sobre su predecesor. Representa un salto cualitativo en lo que respecta a las habilidades emergentes en robótica. A través de experimentos en más de 6,000 pruebas robóticas, el RT-2 ha demostrado habilidades en tres categorías clave: comprensión de símbolos, razonamiento y reconocimiento humano. Estas habilidades permiten al robot interactuar con su entorno de manera más intuitiva y efectiva.
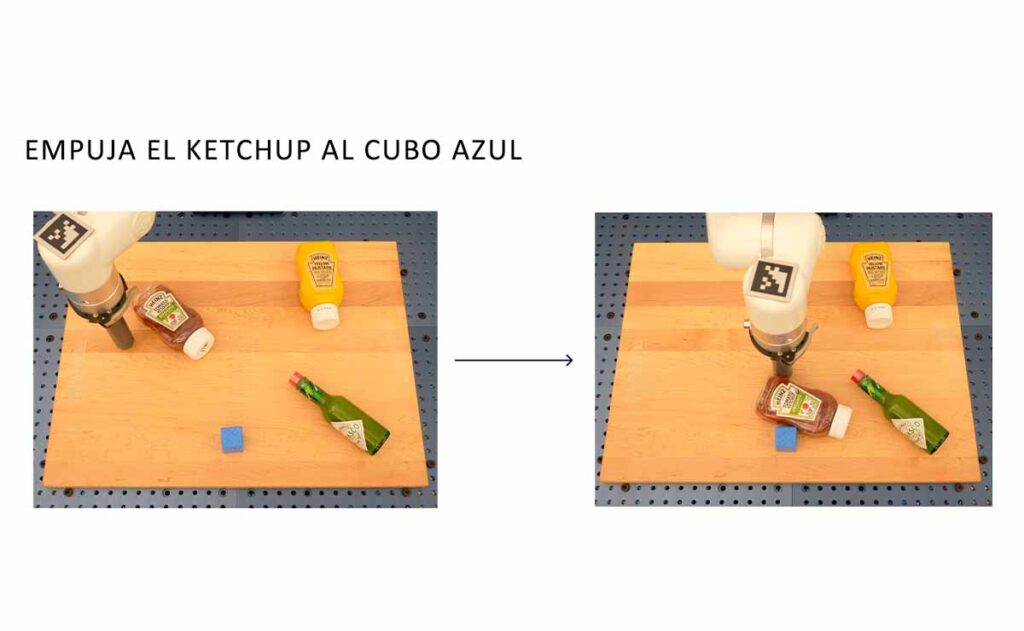
Por ejemplo, el RT-2 puede comprender y actuar sobre comandos como "recoger la bolsa que está a punto de caer de la mesa" o "mover el plátano a la suma de dos más uno". Estas instrucciones, que requieren una combinación de comprensión lingüística y visual, así como una traducción precisa a la acción robótica, demuestran el poder del RT-2 para fusionar la visión, el lenguaje y la acción.
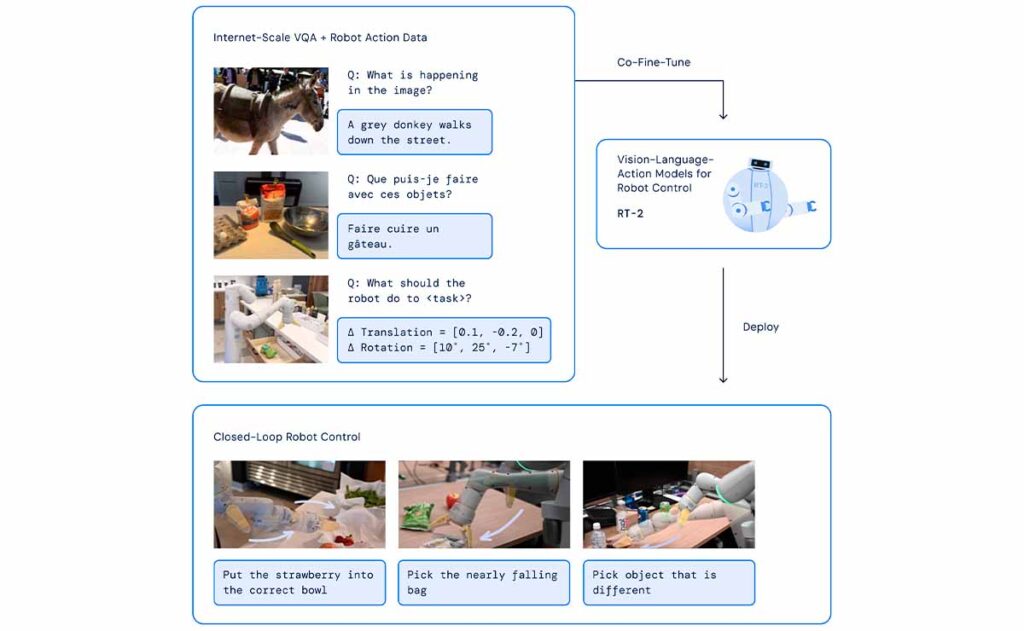
Además, el RT-2 muestra cómo los modelos de visión-lenguaje pueden transformarse en potentes modelos vision-language-action (VLA). Al combinar el preentrenamiento de VLM con datos robóticos, el RT-2 no solo mejora las políticas robóticas existentes, sino que también establece un nuevo estándar en términos de generalización y habilidades emergentes.
Beneficios Futuros de RT-2: Hacia una Nueva Era de Robótica Inteligente
Los beneficios tangibles que podemos esperar de la tecnología RT-2 en el futuro incluyen:
- Generalización y Habilidades Emergentes: Uno de los desafíos más grandes en la robótica es la capacidad de un robot para generalizar y adaptarse a situaciones no vistas durante su entrenamiento. RT-2 aborda este desafío de manera impresionante. A través de experimentos en más de 6,000 pruebas robóticas, el modelo ha demostrado habilidades emergentes en comprensión de símbolos, razonamiento y reconocimiento humano. Estas habilidades permiten al robot interpretar y actuar sobre comandos complejos, como "recoger la bolsa que está a punto de caer de la mesa" o "mover el plátano a la suma de dos más uno". Estas acciones, que requieren una combinación de comprensión lingüística y visual, demuestran la capacidad del RT-2 para fusionar información de múltiples dominios y actuar de manera coherente.
- Control Robótico Avanzado: El RT-2 no solo mejora las políticas robóticas existentes, sino que también establece un nuevo estándar en términos de generalización y habilidades emergentes. Al combinar el preentrenamiento de modelos de visión-lenguaje con datos robóticos, RT-2 ha demostrado ser una modificación simple pero efectiva sobre los modelos VLM existentes. Esta combinación promete la construcción de robots de propósito general que pueden razonar, resolver problemas e interpretar información para realizar una amplia variedad de tareas en el mundo real.
- Un Futuro Prometedor: El RT-2 de DeepMind es más que una simple actualización o mejora sobre modelos anteriores. Representa una visión del futuro de la robótica, donde los robots son verdaderamente inteligentes, adaptativos y capaces de aprender de su entorno de manera efectiva. Con la capacidad de combinar el vasto conocimiento de la web con experiencias robóticas prácticas, el RT-2 está preparado para liderar una nueva era de robótica inteligente. A medida que esta tecnología continúa evolucionando, podemos esperar ver robots más versátiles, intuitivos y útiles en una variedad de aplicaciones, desde el hogar hasta la industria y más allá.



